
I recently had the pleasure to run a demo on how persistent storage is provided for Kubernetes using Pure Service Orchestrator (PSO) in front of our FlashCrew customers in Madrid. I want to review here that demo and highlight some key facts.

First thing is that Pure is API first, so all storage is consumed via APIs. This is key when trying to consume infrastructure in a simple way. The fact that you do not have to define aggregates, pools, raid groups (you name it), etc is another important factor. All Pure users know about the performance and latency guarantees of Pure. Users only need to specify what is the size of the volume they want. This is important when consuming storage for microservices.
All cloud providers are disaggregating compute and storage. Here PSO helps by defining a fleet of Pure arrays, together with the properties of them, so PSO can decide on real time what is the best array to provision storage to the compute resources belonging to the Kubernetes cluster.
With one command we define the arrays available for the Pure Storage Class. Here one example used in the demo:
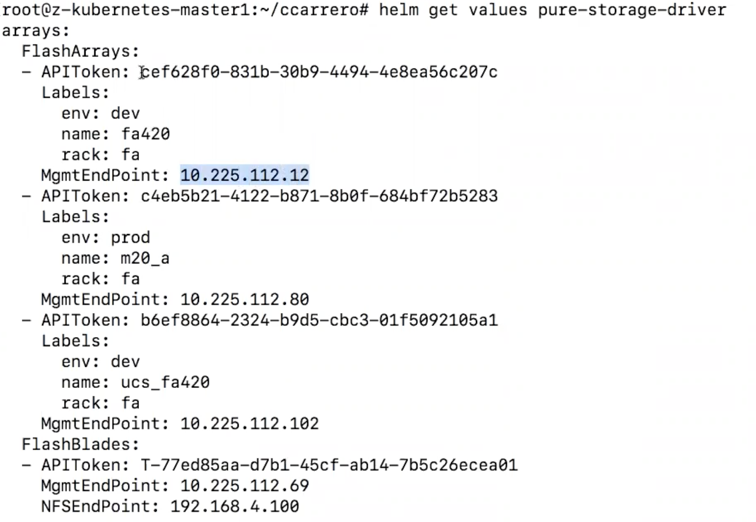
We just need to define the IP address and the API token to access each array. We also define the labels so each Kubernetes pod can request the right class of storage needed. PSO will filter that request and find the most appropriate array.
In the demo I showed how to create a pod that runs a container with a Postgres database. The first thing is to define the Persistent Volume Claim to be used. This is done with this yaml file:
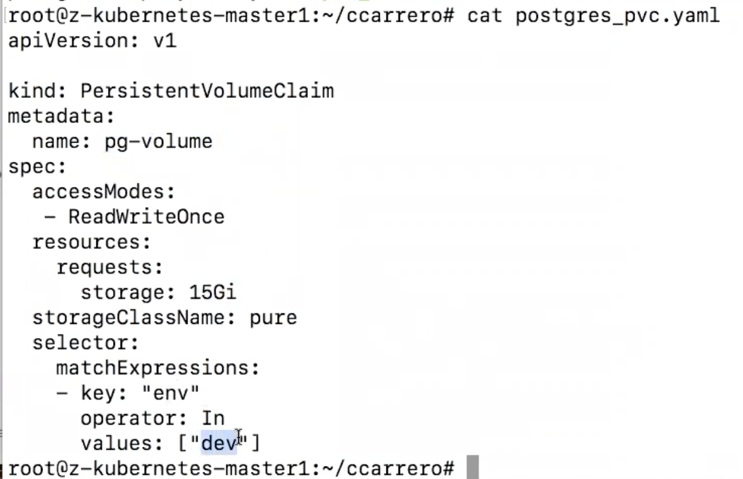
We are creating a PVC called pg-volume of 15Gi and looking for a “dev” type array (we have two in our fleet)
Once executed, we can see how a PVC is created:

And that creates a volume within the array without any user intervention:
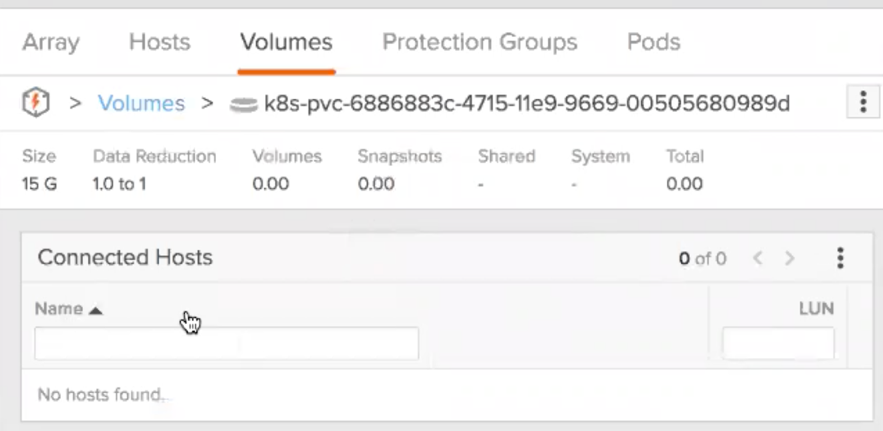
At this point, the volume is not connected to any host yet. Our next step is to define the pod that will run the Postgres container. Let´s take a look to the yaml file:
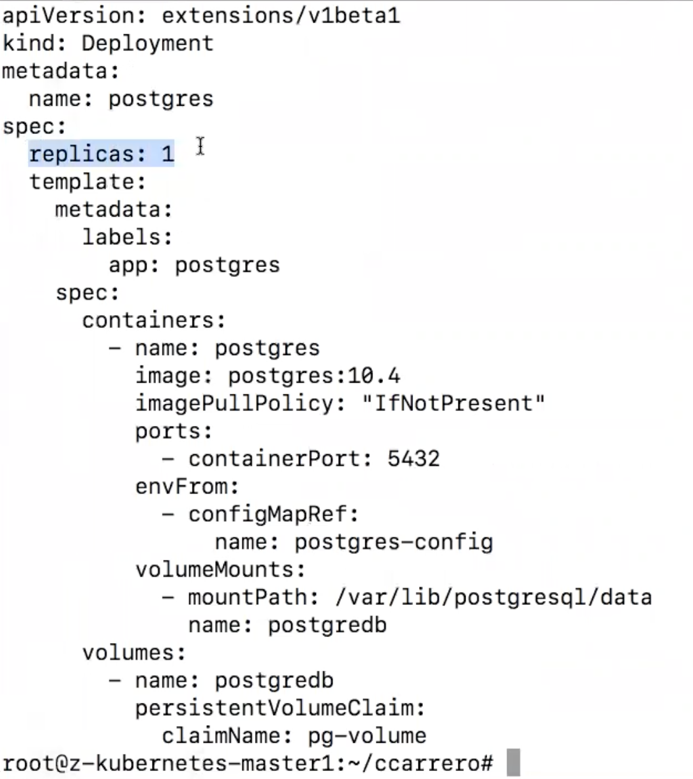
You can see how we define a deployment that will require 1 replica at all time. Kubernetes will make sure that one container will be always running. Within the container, we also define the mount point where Postgres will store the data, and how that is associated to a volume that will be using the Persistent Volume Claim previously created.
Once we run this definition file, we can see how the pod is created and associated to the PVC:
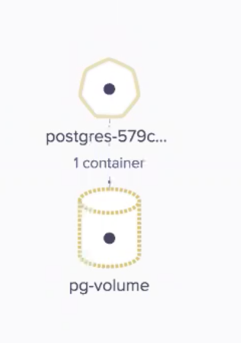
During the demo we also demoed how we can access the container and create some data in the data base. Once Kubernetes run the container, it will choose what is the most appropriate node to run the pod. Automatically, the volume will be mapped form the array to that host. Now we can see how the volume is connected to host5:
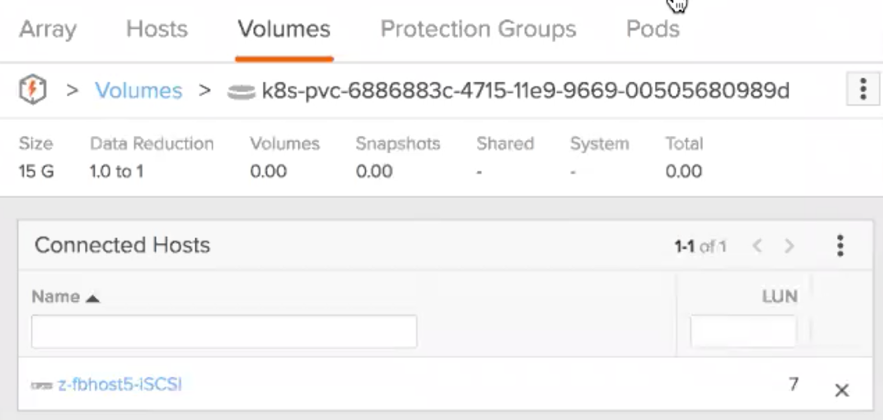
Again, all this happened without any user intervention. Because we have defined replica equals 1, if the pod dies or the server where it is running have any issue, Kubernetes will make sure the pod is running somewhere else.
If we force a failure in the pod, we can see how it is automatically restarted. Kubernetes will choose what is the most appropriate node to run the new container.
Here we can see the moment the new pod is being created:
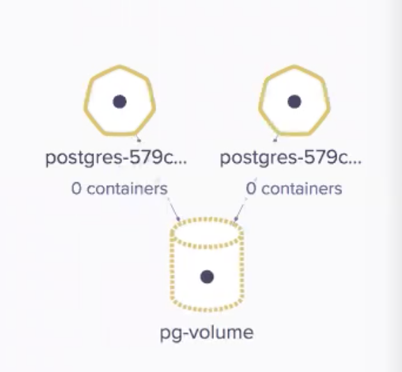
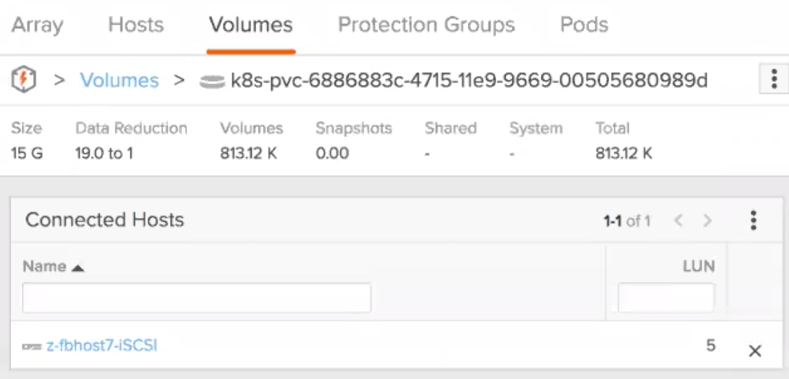
The volume will follow the pod wherever it is started. Before the pod was running at host5 but after the restart, we can see how the volume has been disconnected from host5 and connected to host7 as the pod is now running at that node:
At the demo, we also showed a different configuration with another database using 3 replicas:
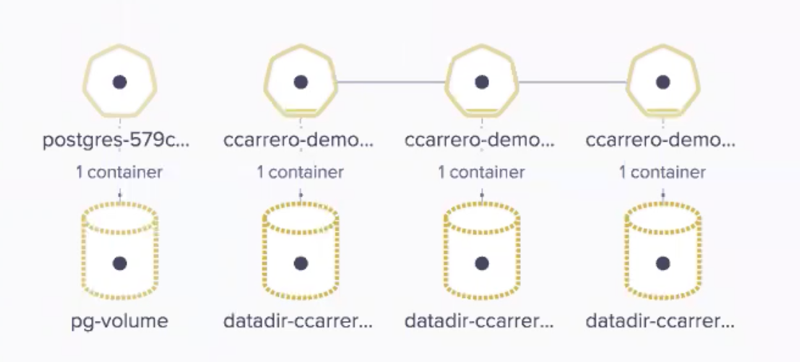
Given the advantages of Pure on data reduction, and now taking advantage of NVMe-oF, this is a perfect use case where Pure can provide the performance and latency needed or those services, without the need of DAS, and taking all the advantages of enterprise storage.
As a summary, I hope you have seen how PSO completely automates storage consumption and management for Kubernetes. This level of automation is what every IT house should be looking for. Cloud is not a place but a concept on how to consume and provide services. If you are working on storage and you are still provisioning using manual process you are definitely wasting your time and probably your job will be redundant pretty soon. Try to up-level your skills and get some training on code writing and automation tools. That is the way to go in an agile data center.
Of course, that is just my personal advice.
Carlos.-