

En la primera entrada de este blog hablaba de la importancia de contar con datos para poder entrenar nuestros sistemas de Inteligencia Artificial o de Machine Learning. Para aquellos que tienen cierta familiaridad con Machine Learning, probablemente han visto los ejemplos de Andrew Ng explicando la creación de modelos para estimar el precio de un inmueble. La siguiente gráfica es una simplificación donde hay dos variables: los metros cuadrados del inmueble y el precio. El precio es la variable que se quiere estimar y los metros cuadrados es la característica o ¨feature¨ con la que se cuenta para realizar dicha estimación
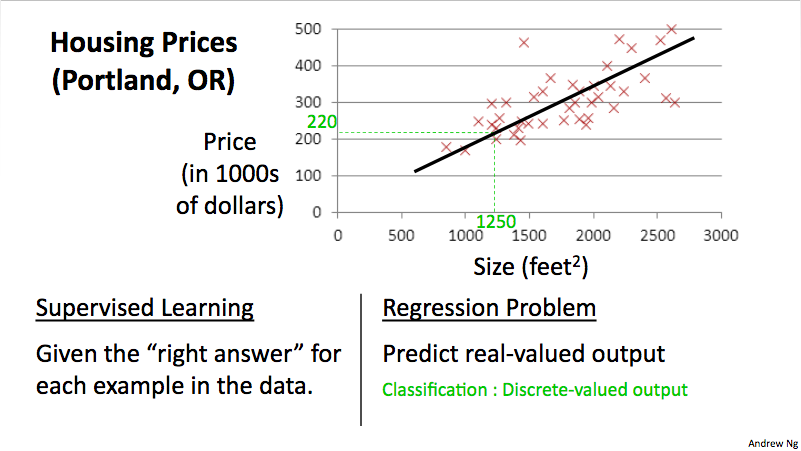
El objetivo es estimar el precio adecuado basándose en las características del inmueble. Esa estimación al final se basa en una ecuación donde se multiplican cada una de las características por un peso que ha sido asignado a cada una de ellas. Para encontrar el valor adecuado de ese peso se utiliza el conjunto de aprendizaje (los datos que tenemos sobre características de casas y sus precios) que se pasará como entrada al algoritmo de aprendizaje.
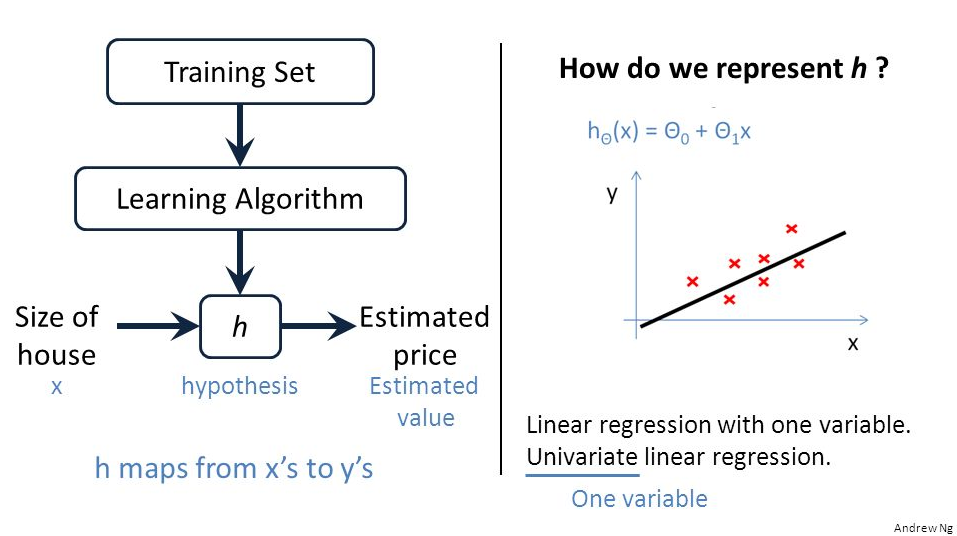
Un aspecto clave es contar con la mayor cantidad de información posible sobre características de inmuebles y sus precios. Cuantos más datos, mejor y más acertado será el aprendizaje. En el ejemplo dado solo se utilizan los metros cuadrados. Para obtener mejores resultados, se pueden utilizar más características como número de habitaciones, antigüedad, estado del inmueble, etc.
¿Cómo se puede aplicar esto cuando hablamos de plataformas de datos? En el primer artículo comentaba que Pure Storage recoge 1 trillón de métricas de sus clientes al día que obtiene de la telemetría. En este video Farhan Abrol explica cómo Pure1 Meta utiliza parte de esa información para poder ayudar a sus clientes a predecir cargas de trabajo:

El objetivo es poder estimar la carga de trabajo o ¨load¨ del sistema en un tiempo futuro. Las ventajas son claras, pues ayuda a los clientes a hacer un correcto dimensionamiento de los sistemas y además estimar de forma precisa nuevas necesidades, así como hacer simulaciones con la utilización de nuevos componentes. Cuanto más preciso sea el modelo creado, mayor beneficio tendrá para el cliente.
Esta carga del sistema Pure1 la define con un valor entre 0 y 100 (tendríamos la analogía del precio del inmueble) y se calcula en base a distintos parámetros de utilización del sistema. Al igual que el precio de un inmueble lo determinará sus características como metros cuadrados, habitaciones, etc, en el caso de almacenamiento, las características las definen el tipo de workload, que viene definido por parámetros como número de lecturas y escrituras, operaciones por segundo, patrones de sobre-escritura, etc. Es decir, estas son las características que se utilizan para poder estimar la carga.
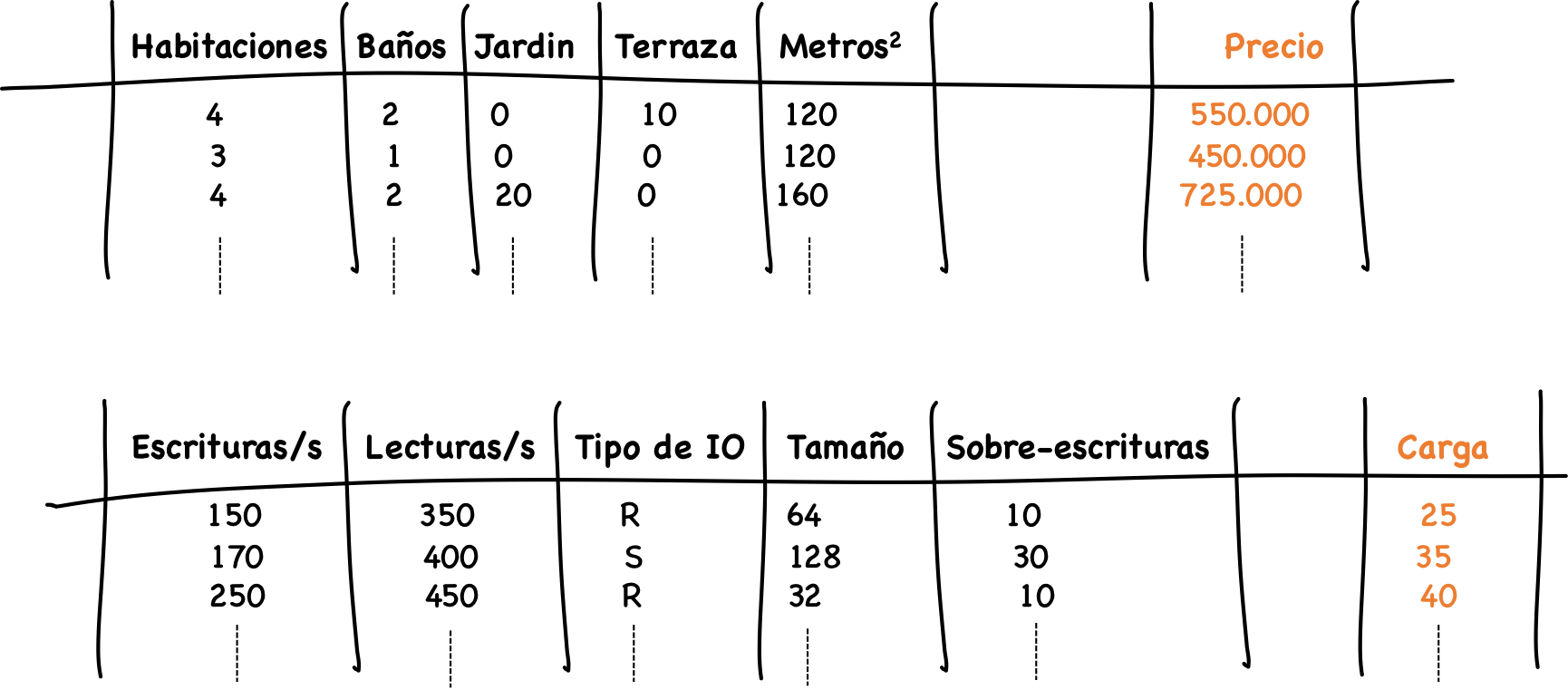
Para predecir la carga de trabajo, Pure1 utiliza todos los datos que tienen disponibles basada en la telemetría de todos sus sistemas. Es decir, Pure1 cuenta con muchos datos de entrenamiento (training set) etiquetados, lo cual es clave para poder hacer un entrenamiento supervisado.
Con toda esa información se crea un modelo que puede predecir cuál será la carga del sistema (en un valor de 0 a 100) dado unos parámetros hipotéticos de entrada para una carga de trabajo futura. Para hacer esa proyección en el futuro, Pure1 además utiliza análisis de series temporales para encontrar cual es la tendencia en la carga de trabajo para cada una de las características que se utilizan con el modelo creado anteriormente.
En resumen, la base de un buen sistema de Machine Learning con aprendizaje supervisado es tener mucha cantidad de datos etiquetados que contienen suficientes características. Ya sean inmuebles o plataformas de datos!
Carlos Carrero.-
Interesante artículo, Carrero.
La cuestión es una vez estimada una determinada carga del sistema “x” para un determinado tiempo “t”, ¿qué mecanismos tiene Pure1 para satisfacer dicha demanda “x” a la hora “t”? O dicho de otro modo:”cómo es capaz de re-dimensionarse dinámicamente para satisfacer dicha demanda predicha ¿Se utilizan esas estimaciones para dimensionar dinamicamente el sistema, o solamente como indicadores estáticos que puedan llevar a recomendar al cliente actualizar o ampliar sistemas?
Saludos,
Hola Gonzalo! Que bueno leerte por aquí! Gracias por tu comentario.
Yo creo que lo del tuning y redimensionamiento debería ser ya cosa del pasado. Todo el mundo busca simplicidad y la razón es que es mejor gastar el tiempo en cosas mas productivas y mas relevantes para el negocio que administrar LUNs. Desconozco en profundidad como funciona el array de Pure y la razón de mi artículo se basa en su utilización de datos para crear algoritmos de Machine Learing. Pero me parece interesante comentarios como este que puedes ver en su página web:
¨We aim to eradicate all the complexity of traditional storage – and the management tasks surrounding that complexity. No more tuning, storage pools, caching, tiering, performance troubleshooting, planned downtime, forklift upgrades, and the rest. Instead, we’ve created a Data Platform that manages itself through machine learning predictive intelligence. If there’s ever anything that needs your attention, your smartphone will let you know.¨
Pero insisto, que lo que es relevante para mi en el ámbito de este artículo es que para poder hacer Machine Learning hacen falta datos. Esto es algo que se suele pasar por alto. Y creo que es importante que desde el inicio Pure ha estado recogiendo datos que posiblemente ahora le permitan hacer cosas de forma mas inteligente. ¿Por qué Apple tiene un sistema muy bueno de reconocimiento de caras? Básicamente porque todos los usuarios le hemos estado dando fotos con tags y ahora tienen millones de fotos para entrenar sus algoritmos. Yo puedo tratar de hacer el mejor algoritmo posible, pero no tengo lo que Apple, Facebook, Google, etc tienen: Datos.
Un abrazo!
Carlos.