
I must be a lazy person. During my career at IT, once I had to do something three times, I was looking for ways to automate it. My first task as an intern at Sun Microsystems was to create a detailed report for all server’s deployments. Professional Services Engineers were bringing a file called Explorer with all the server HW and SW configuration. I created a tool called “etoh” or Explorer-to-HTML that automated all the process. We not only saved a full day of work but we also had all the information online, searchable and shared with colleagues at Support Services. And of course, I had a full day free to keep evolving myself with other tasks.
Once I moved to Professional Services as a full Engineer I was in charge of many E10K server deployments. You had to install the OS, apply patches, customize the environment, add storage, mirror the boot disk, etc. A lot of repeatable tasks. I decided to invest some time to automate the full process using JumpStart. At the end, I had created a fully automated process to create a complete full deployment with a single click. The only think I was doing was spending one hour at the beginning setting up the JumpStart configuration at the customer site for the first time. In a typical one week engagement, I had the rest of the week free for me. Well, really, I had the rest of the week to keep progressing my skills.
At Veritas we had a lot of fun (my ex-colleagues will argue with me what is the concept for fun) at Support Services once NetBackup 6.0 replaced the traditional job scheduler based on bpsched daemon to a new one called IRM (Intelligent Resource Manager). The first version was not so “Intelligent”. Working at backline support I was receiving the top escalations in the world when something was not working properly. At the end, it was a tedious work tracing a NetBackup job from start to end (or start to hung). So again, here we had another opportunity to automate. This was more complex because as my estimated colleague and mentor Peter F. said, it was about having “Carlos-in-a-box”. The result was IRMA (Intelligent Resource Manager Analyzer) that was able to get all the NetBackup logs and trace every single job, represent it in an HTML page and add some extra knowledge to pin-point any possible delay in the job execution. This helped us to discover the “butterfly effect”, or how a small 1 sec delay in a database transaction were affecting the rest of jobs that had to sit in the queue.
Maybe I am not lazy as all of this was hard work. Maybe what I like is to have repeatable and fault proof results. Once you generate a report, you don’t’ have any errors. You don’t’ want to leave a serer deployment with the doubt if an important volume was protected or not, and when a NetBackup user had an escalation, you wanted to help the user to pin-point and correct the error in no time.
All this happen very long time ago, but nowadays we cannot think about IT without automation. Automation is in the core of the business. This provides not only the agility, but also the ability to get the same results again and again. With Infrastructure, you want to make sure you can press a button and always get the same results.
It is quite interesting what companies are doing to automate their deployment methods. One key thing for any product will be being API driven. In this sense, companies that are creating products with a blank sheet of paper (rather than legacy products that are much more complex to adapt) are using APIs as the core of the product. One example is Rubrik’s API-first architecture. Their HTML5 interfaces consumes the API endpoints. And anybody can use those APIs. In this article, Rubrik discuss how those APIs can be used to provide proactive data protection during natural events. It is a very interesting use case that leverages all the power of automation. Think also how this could be integrated with AI.
If we take a look to the new announcement for Red Hat OpenStack Platform 12, we can see two main pillars: Ansible and Containers. With Ansible, Red Hat is driving automation to the next step. While I was working at Veritas with HyperScale for OpenStack, our engineers had to work hard to make sure that the full HyperScale deployment fit into a Playbook. The goal is to achieve fully automated deployments. Or get your cloud with a single click.
Containers use case is quite interesting. Products are containerizing now their own components. Red Hat starts with their control plane. Now they provide independent components. This reduces a lot of complexity within OpenStack, with complex overlapping library dependencies that must be accounted for every upgrade or change. Not only that, Red Hat is encouraging all their partners to run their services within a container. For example, HyperScale for OpenStack will be delivered in a container format.
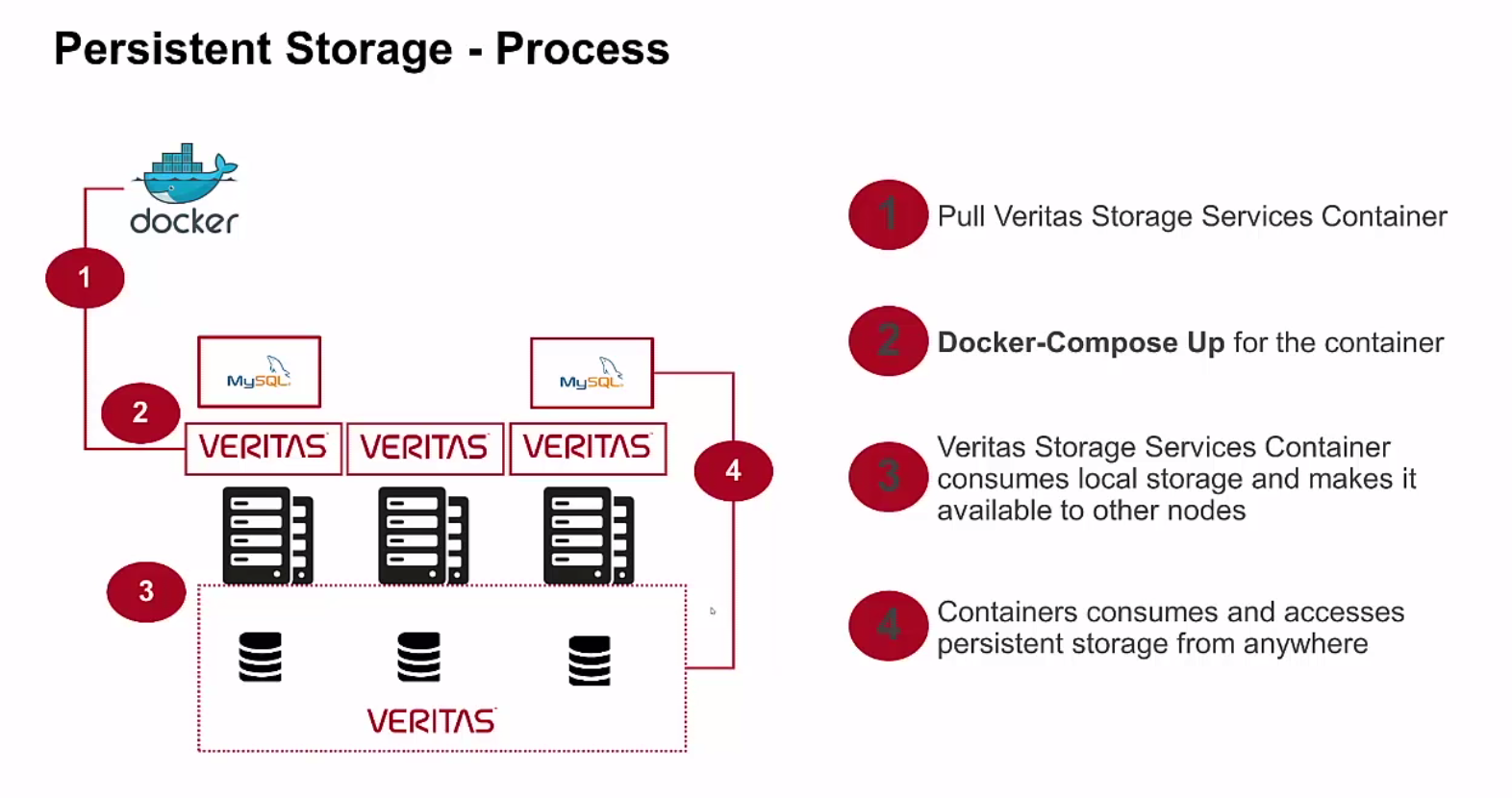
Every single company should be delivering their products in a container format. It is much more simple and agile. As one personal example, at Veritas we were exploring how to provide persistent storage for containers and we had the idea of Storage Services. This had to be quite simple and just another container and you could pull and run.
What we did in a first state was to run our Veritas Cluster Server using Flexible Shared Storage (or shared nothing as I call it) within a container. Take a look to this demo I created:
The beauty here is that something as complex to setup as Storage Foundation Cluster File System (well now it has also evolved to run automated deployments) it was now super-simple because we were using containers. My colleagues at engineering had automated the full process and you only had to pull and run the container. Within two steps, we were providing Storage Services for containers. We presented this concept at VISION 2016 conference during a lab and it was a sound success. All this evolved into HyperScale for Containers product using a new architecture but with similar simplicity concepts.
The move for Red Hat to provide services within Containers in OpenStack is not arbitrary. It is a well taken decision. Also, if you take a look to Red Hat OpenShift they use the same concept with containers to encapsulate each component. Simplicity, security and agility.
Containers can also be leveraged with Data Science. Now I am working in a personal new project to provide data analytics and recommendations for ski resorts. Here I am using Containers in my Mac as a way to isolate my databases and python scripts. Later, I will be able to move these containers to more powerful servers to get faster results. All is fully automated, isolated and sharable!
If you are a ski fun keep tuned. SnowFlix is coming!
Carlos Carrero.-